AI产品经理必修课:你必须知道的Token要点
这是一份写给非技术岗的产品经理/运营的token应用指南。可以在了解token概念的同时,也能够知道设计产品时和token相关的注意点。

自从2022年末OpenAI推出通用大语言模型ChatGPT后,这两年各种大语言模型层出不穷,眼花缭乱。可能你们公司也蠢蠢欲动,“我们也要做AI+产品!”。接着你所在的产品部门喜获一个Epic,“研究如何引入AI升级原本的产品”或者“研究引入AI是否可以找到新的增长点”。
这个时候还没怎么了解AI的你,会怎么迈出第一步?你可能已经是LLM的重度使用者,也可能是刚刚体验的小白。但本着产品经理特有的好奇心,你可能最先想知道的是,大语言模型究竟有什么魔法,竟然可以“听”懂我们的问题,并给出恰当的回答,有时候给到的回答甚至还满让人惊喜的。接着可能就会思考,那我们到底可以怎么使用大语言模型这个全能型”机“才呢?
Token作为大语言模型最基本的概念之一,可能很容易在你搜索相关资料的时候频繁出现。
在这里小小剧透一下,token不仅是了解大语言模型时最先接触到的基本概念之一,它也很有可能从此颠覆你某些产品技能,从商业分析到产品定价,从用户体验到产品决策,都可能因为这个小小的概念让你产品技能的做法或流程变的很不一样。
一、Token的基本概念那到底什么是token呢?Token就是指文本中最小的有意义的单位。是不是有点抽象?我们来通过一个简单的例子看下大语言模型是怎么回答我们的问题,并理解token到底是什么。
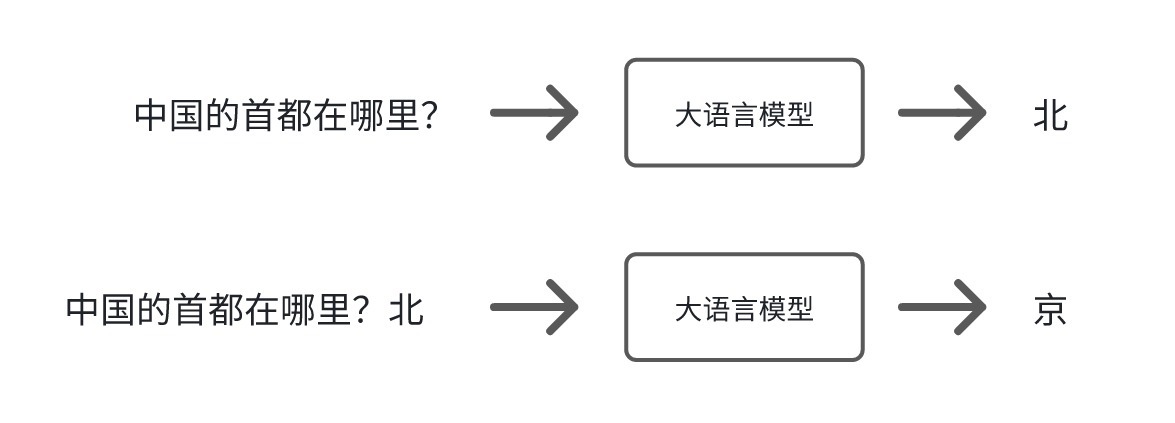
1. 大语言模型怎么回答我们的问题?当大语言模型收到我们一个问题,它的运作原理其实很简单,用一个我很喜欢的教授说的一个很形象的比喻,就是在做文字接龙游戏。也就是给它一个没有完成的句子,它帮你补完。在补句子的过程中,它会预测接下来接哪个字是最合理的。
比如问大语言模型,“中国的首都在哪里?”,它会觉得可能接“北”最合理,然后把输出的内容接在你的问题后面,所以这次的输入就变成,”中国的首都在哪里?北“,这个时候它会觉得接”京“最合理。接下去重复上一个步骤,然后发现接好”京“之后看起来没什么好接的了。就觉得这句句子补完了。那”北京“就是它回答的答案。
 2. Token到底是什么
2. Token到底是什么我们给大语言模型一个未完成的句子,后面可以接的字有很多不同的可能。比如输入上海大,可能是上海大学,可能是上海大楼,可能是上海大师赛等等等等。
实际上大语言模型的输出就是给每一个可以接的符号一个机率。”学“是一个符号,”楼“是一个符号,”师“也是一个符号。所以它的输出其实就是一个几率分布,即给每一个可以选择的符号一个机率。然后按照这个几率分布投骰子,投到哪个符号,那个符号就会被输出出来。这些符号又叫做token。
这就是我们经常所说的,大语言模型的本质上就是在预测下一个token出现的概率。也正是因为这样,即使问大语言模型相同的问题,每次产生的答案可能也都是不一样的。因为每次的回答都是有随机性的。

就如同我们设计MVP产品的时候,最困难的事情不就是怎么定义这个Minimum么?那”文本中最小的有意义的单位“里的“最小”指的是什么呢?一个字?一个词?
这件困难的事情在训练语言模型时就交给了模型开发者,模型开发者会预先设定好token,用于平衡计算复杂度和语言信息的覆盖,所以这里的“最小”可能是一个单词,可能是一个子词,也可能是一个字符。
正因为每个模型在开发的时候会设定好token,所以
不同的语言模型,定义的token可能不一样中文的语言模型和英文的语言模型定义的token可能也不一样接下来,每个token都会被转换成一串对应且不变的数字,因为基于神经网络的语言模型不能理解文本,只能理解数字。
所以,一个模型的token总量可以理解为这个模型的词汇表。而每个token都是一连串的数字,且这个数字是不变的。
二、大语言模型中token长度限制模型能够同时处理token的数量,叫做token的长度。这个长度是有限制的。比如我们使用一个模型,它的token限制是4096个token,这就意味着你在一次请求中,输入和输出的总token数不能超过4096个。
Token长度限制很容易和上下文窗口限制混淆。
上下文窗口限制指的是模型在一次交互中可以”记住“多少信息,也就是在整个对话过程中可以使用的最大token数。上下文窗口决定了模型对输入内容的理解深度和生成输出的能力。比如,模型的上下文窗口大小是4096 token,那么无论你对模型输入多少次信息,所有这些输入和生成的内容加起来不能超过4096 token。一旦超过,最早输入的内容可能会被”遗忘“,从而无法用于生成新的输出。
总结来说,
token长度限制指模型一次输入或输出的总token限制数。上下文窗口限制指整个对话过程中,模型能够处理所有token的最大数量。举个例子
假设我们在玩传纸条游戏,我们只能在纸条上写下4096个字符的内容,也就是说我们之间所有的交流内容不能超过这个长度。这个就是“上下文窗口限制”。一旦纸条上的内容超过了4096个字符,就必须把最早的内容擦掉一些,才能写下新的内容。而“token限制”就是我们每次传纸条最多能写的字符,比如我们设置了我们每次传递最多只能写200个字符。那如果在一次传递中我已经写了180个字符,你就只能写20个字符。
三、设计产品时,token会给到你的”惊喜”和”惊吓”“惊吓”:token 从技术单元转化为计费单元,并且可能比你想象的更贵!
影响:引入大语言模型后,当我们分析ROI时,如果没有把token的使用成本考虑进入,不仅不能为公司产生利润,还可能赔钱。有些时候,token的使用成本甚至可能改变产品的定价策略。
举例:
企业有一个线上模拟练习的产品,专门为用户提供在特定场景下的技能练习,从而让用户通过刻意练习后在实际工作中也能稳定的发挥所需的技能。通常当我们分析这个产品的ROI时,成本这边可能最大的投入是一次性的研发成本以及后续的软件维护成本。
企业想要引入大语言模型升级这个模拟练习产品,这样可以让用户有更真实的体验从而达到更好的练习效果。当我们分析这个产品的ROI时,不仅要考虑研发成本等,还需要计算出用户每练习一次token所产生的成本,这个成本不仅仅是产品发布后用户使用时会产生的,在产品研发测试、GTM的过程中都可能产生。而这些成本不仅会影响GTM Stragety,也会影响到后续的产品定价。
产品经理只有把token相关的影响因素都充分考虑后,才能提升用户体验的同时还能保证产品盈利。
“惊吓“:更好的体验?呃,也许没那么美好。影响:我们都知道在互联网时代性能体验有一个原则是2-5-10原则,也就是当用户能够在2秒以内得到响应时,会感觉系统的响应很快,而在2-5秒间会觉得还可以,在5-10秒间觉得勉强可以接受,但是当超过10s时,用户会因为感觉糟透了而离开你的产品。但是当我们引入大语言模型后,我们很有可能为了更好的功能用了很长的提示词,用户很有可能因为等待时间过长直接离开了产品,甚至都没有机会体验到AI带来的功能提升。
举例:还是上面那个例子,企业想要引入大语言模型升级模拟练习产品,这个模拟练习中有一个NPC会和用户互动。为了让NPC能够根据用户的输入给到更精准的反馈,我们给到NPC一个非常详细的剧本,包含了方方面面的考量。NPC确实能够非常精准的回复用户每次的输入,但是用户每一次输入之后都需要等待10秒以上,如果这个练习的互动是很多轮次的,那显然用户是没有这个耐心完成练习的。
产品经理找到准确性和用户体验的最佳平衡点,才能让用户感受到AI带来的更好的体验。
”惊喜“:效果太差?不,只是token限制了模型发挥。影响:在互联网时代,一旦我们设计产品功能没有达到我们的效果,或者技术实现成本过高或有困难的时候,我们需要一起讨论并修改整个产品。而当你的想要达到的功能是基于大模型时,有时候你只需要做一个动作,就是换一个大预言模型,产品功能就达到我们的预期效果了。
举例:
企业想要把私有知识库搬进大模型,这样但凡之后用户问到和这个领域相关的问题,AI就能表现的非常专业。但是有些知识库非常庞大的。在前面token长度我们了解到,大语言模型对于token是有限制的,如果我们选择了一个模型,它的token限制是4096,但是可能其中一个知识库本身的量级已经占用了3000个token,再加上相关的提示词所需要的token数,知识库的3000个token在2500个token的时候就被截断。这个时候当用户问到相关知识的时候,准确率只有60%。但是当我们换了一个模型,它的token限制是8192,那么准确率一下子就飙升到92%并达到了产品设计时的期待。
四、结语Token是语言模型中一个非常重要的基本概念,我们越了解token,就可以越有效地利用大语言模型,从而帮助我们在设计AI+产品时更加的游刃有余!
本文由 @AI 实践干货 原创发布于人人都是产品经理。未经作者许可,禁止转载
题图来自Unsplash,基于CC0协议
该文观点仅代表作者本人,人人都是产品经理平台仅提供信息存储空间服务
